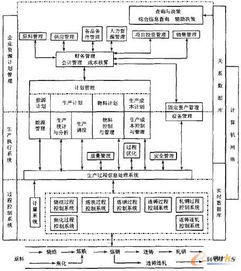
计算机集成制造系统(CIMS)是现代钢铁企业提升生产效率、优化资源配置、增强市场竞争力的核心支撑。邯郸钢铁集团(以下简称“邯钢”)作为国内重要的钢铁生产基地,其CIMS的设计与实施,尤其是数据处理环节,构成了整个系统高效、可靠运行的基石。本文将聚焦于邯钢CIMS中数据处理系统的设计理念、架构与具体实施路径。
一、 数据处理系统的总体设计目标
邯钢CIMS数据处理系统的设计,旨在打破传统“信息孤岛”,实现从原料采购、生产调度、工艺控制、质量管理到仓储物流、销售服务全流程数据的集成、共享与深度利用。其核心目标包括:
- 数据集成化:统一数据标准与接口,整合来自基础自动化(L1)、过程控制(L2)及企业资源管理(L3)等不同层级、不同格式的海量数据,形成一致、准确的全厂数据视图。
- 处理实时化:满足生产现场对关键工艺参数(如温度、压力、成分)实时监控与快速响应的需求,确保数据采集、传输与处理的低延迟。
- 服务智能化:通过对历史数据与实时数据的分析、挖掘,为生产优化、质量追溯、故障预警、能源管理等提供智能决策支持。
- 系统高可靠:建立完备的数据备份、容灾与安全机制,保障生产数据在复杂工业环境下的完整性、可用性与机密性。
二、 数据处理系统的架构设计
为实现上述目标,邯钢CIMS采用了分层、分布式的数据处理架构:
- 数据采集层:部署在生产一线的数据采集网关与接口服务器,负责从PLC、DCS、智能仪表、条码/RFID等设备中自动采集原始数据,并进行初步的滤波、校验与格式标准化,形成统一的实时数据流。
- 数据集成与存储层:构建了企业级实时数据库与关系数据库双核心的存储体系。实时数据库用于高效存储和快速访问带时间戳的过程数据;关系数据库则用于存储生产订单、质量检验、设备档案等结构化业务数据。两者通过数据总线进行同步与关联。
- 数据处理与计算层:该层部署了数据清洗、转换、加载(ETL)工具以及流式计算引擎。它负责对原始数据进行更深层次的清洗、整合、归档,并运行关键性能指标(KPI)计算、统计过程控制(SPC)分析、物料平衡核算等核心业务逻辑。
- 数据服务与应用层:以数据仓库和数据集市为基础,通过统一的API接口或数据服务平台,向MES(制造执行系统)、ERP(企业资源计划)、质量管理系统、设备管理系统等上层应用提供标准、可靠的数据服务,支撑各类业务分析与决策。
三、 关键实施策略与技术要点
在具体实施过程中,邯钢重点关注了以下环节:
- 统一数据编码与标准:在项目初期,即制定了覆盖物料、设备、工艺、人员等全要素的企业数据编码规范,这是实现数据集成与共享的前提。
- 构建高性能数据通道:采用工业以太网与OPC UA等开放协议,建设了高速、稳定的厂级数据网络,确保海量实时数据能够无阻塞传输。
- 实施渐进式数据迁移:面对庞大的历史数据,采取“新旧系统并行、分阶段迁移”的策略,先确保实时生产数据的平稳接入,再逐步迁移历史归档数据,最大限度降低对现有生产的影响。
- 强化数据质量管理:建立了贯穿数据全生命周期的质量管控规则,包括源头校验、过程监控与事后审计,并利用数据质量工具定期评估与修复问题数据,确保“数据可信”。
- 开发主题分析模型:针对钢铁生产的特点,开发了面向“炼铁-炼钢-连铸-热轧-冷轧”全流程的物料跟踪、质量追溯、能源消耗、成本核算等主题数据分析模型,将数据转化为 actionable insights(可执行的洞见)。
四、 实施成效与展望
通过系统化的设计与实施,邯钢CIMS数据处理系统取得了显著成效:生产指令下达至反馈的周期大幅缩短;关键工序的质量数据在线监控率达到100%,质量异议追溯时间从数天缩短至数小时;基于数据的能效分析与优化,实现了显著的节能降耗。
随着工业互联网、大数据与人工智能技术的深度融合,邯钢的数据处理系统将进一步向云端协同、边缘智能、预测性维护等方向演进,持续驱动钢铁制造向数字化、网络化、智能化转型升级,夯实企业高质量发展的数据基石。